

In einem früheren Beitrag haben wir bereits die Unterschiede von Supervised und Unsupervised Machine Learning und ihre Bewertungsmöglichkeiten vorgestellt. In diesem Beitrag widmen wir uns detaillierter den Bewertungskriterien von «Classification» Algorithmen und erklären, warum je nach Anwendungsfall ein Kriterium wichtiger ist als das andere. Wie genau ist also mein Algorithmus?
Was bedeutet «Classification»?
Bei der Classification werden Daten mit einer Kategorie oder einem Ja/Nein-Wert klassifiziert. Diese Einordnung nennt man «Label». Das Ziel bei einer Classification ist es, neue Daten aufgrund bekannter Daten zu kategorisieren. Ein Beispiel aus dem Alltag: Der Eisverkäufer malt sich aus, dass verschiedene Faktoren einen Einfluss haben, wie viel Umsatz er an einem bestimmten Tag machen kann: Wetter, Temperatur, Wochentag, Feiertag, Monatsende, etc. Angenommen er hätte über die letzten Monate jeden Tag Buch geführt, ob sein Umsatzziel erreicht worden ist oder nicht, inklusiv der jeweiligen Faktoren, so kann er mittels Classification voraussagen, ob er am heutigen Tag sein Umsatzziel erreichen wird oder nicht – zumindest mit einer gewissen Wahrscheinlichkeit. Wie genau seine Voraussage ist und somit sein Classification-Algorithmus, kann mit verschiedenen Kriterien gemessen werden.
Wie wird das Resultat einer Classification bewertet?
Bei Classification kann mit der sogenannten Konfusions-Matrix gearbeitet werden. Von dieser können die Messkriterien berechnet werden.
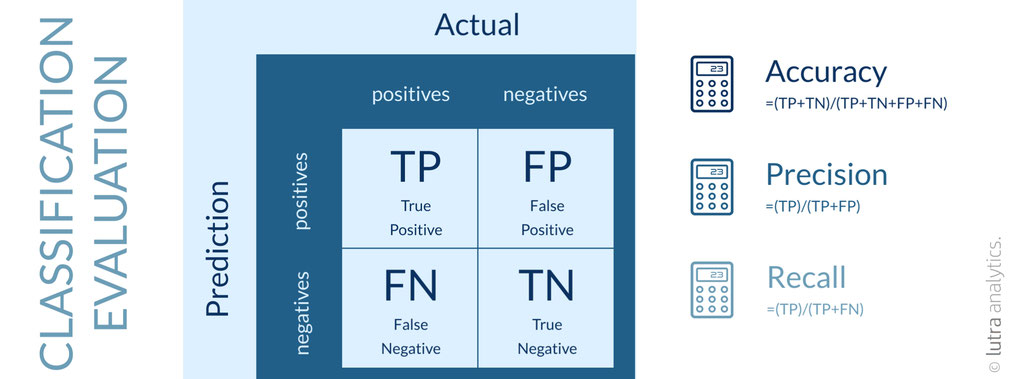
Zurück zu unserem Beispiel bedeutet das:
- True Positive: Das Umsatzziel wurde erreicht und wurde auch so vorausgesagt
- False Positive: Das Umsatzziel wurde nicht erreicht, wurde aber als erreicht vorausgesagt
- True Negative: Das Umsatzziel wurde nicht erreicht, wurde auch so vorausgesagt
- False Negative: Das Umsatzziel wurde erreicht, wurde aber als nicht erreicht vorausgesagt
Da unser Eisverkäufer im Nebenjob Statistiker ist, wagt er das Experiment. Er nimmt seine Datensätze über die letzten Monate und teilt diese in ein Trainings-Set und in ein Test-Set auf. Diese Aufteilung wird immer gemacht, um einerseits den Algorithmus zu erstellen und zu trainieren (Daten aus dem Trainings-Set) und um anschliessend das Resultat mit anderen Daten zu testen (Test-Set).
Das Resultat trägt er nun in seine Konfusions-Matrix ein.
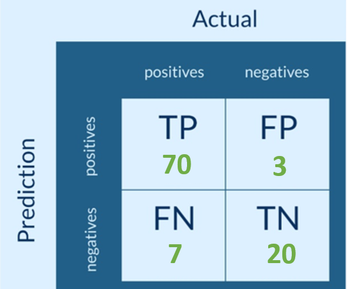
In der Tabelle erkennen wir, dass 100 Tests vorgenommen wurden, wobei die meisten korrekt vorausgesagt worden sind. Wie genau nun der Algorithmus arbeitet, können wir mit den drei wichtigsten Kriterien beurteilen.
Dreifaltigkeit der Messkriterien
Accuracy, Precision und Recall: Die häufigsten Kriterien können nun mit den Werten aus der Matrik berechnet werden.

Da sich alle Werte bei mindestens 90% einordnen, können wir von einem recht anschaulichen Resultat sprechen. Doch was bedeuten nun die unterschiedlichen Kriterien?
Accuracy – wenn unsere Daten ausgeglichen sind
Das verständlichste der Kriterien ist die Accuracy, welche aussagt, wie viel Prozent aller Fälle korrekt erkannt worden sind. Das verleitet dazu, vor allem auf dieses Kriterium zu vertrauen. Das ist aber nur dann sinnvoll, wenn die Voraussagen von Ja und Nein ausgeglichen sind (das heisst, wir haben ähnlich viele positive und negative Fälle).
Ein (leider aktuelles) Szenario sind medizinische Tests, z.B. ob jemand am Corona-Virus erkrankt ist oder nicht. Bei seltenen Krankheiten ist der Anteil an positiven (also somit erkrankten) Personen so klein, dass ein schlechter Algorithmus, der immer das Resultat «negativ» ausgibt, eine Accuracy von über 99% hat. Das scheint ein sehr gutes Ergebnis zu sein, aber unser Algorithmus taugt nichts, da er keine Krankheiten erkennt – und genau diese zu erkennen ist das Ziel, damit bei diesen Patienten (frühe) Massnahmen ergriffen werden können.
Precision – wenn wir präzis sein möchten
Wenn die Kosten von «Falschen Positiven» hoch sind, dann gilt es einen möglichst hohen Precision-Wert zu erreichen. Das heisst, Fälle wurden als positiv eingestuft, sind in Wahrheit aber negativ. Ein Beispiel dazu ist «Spam-Detection»: Wir sind daran interessiert, dass Spam in Mails erkannt wird und gefiltert wird. Der wichtige Auftrag vom Kunden darf allerdings nicht als Spam deklariert werden, sonst geht Geld verloren. In dem Fall würden wir also lieber ein Spam-Mail mehr durchlassen, als dass wir «Nicht-Spam» als solchen deklarieren.
Recall – wenn die Kosten für ein Nicht-Erkennen zu hoch sind
Der Recall ist dann ein wichtiges Kriterium, wenn die Kosten von «Falschen Negativen» hoch sind, also wenn etwas als negativ vorausgesagt wird, aber tatsächlich positiv ist. Ein Beispiel davon sind die Krankheitsfälle vom Beispiel oben. Wir möchten auch bei seltenen Krankheiten den Patienten helfen und somit sind «Falsche Negative» zu vermeiden. «Falsche Positive» sind zwar unschön, aber es hängen dann keine Menschenleben davon ab. Der Recall beschäftigt sich nämlich mit dem Verhältnis von erkannten Positiven zu nicht erkannten Negativen.
Kann ich mit Fehl-Klassifikationen leben?
Ob unser Eisverkäufer, der Mediziner oder die IT Security: Classification kennt unzählige Anwendungsfälle, welche unterschiedliche Messformen verlangen. Man muss sich immer fragen, was eine falsche Klassifikation für eine Auswirkung auf meinen Fall hat. Kann ich mit falsch erkannten Werten leben und wenn ja, wie viele davon kann ich erlauben? Was sind die Folgen davon und kann ich das verantworten?
- Als Eisverkäufer möchte ich keinen umsatzstarken Tag missen, muss dafür aber in Kauf nehmen, dass ich an einem Regentag halt nur minimal verdiene.
- Als Mediziner möchte ich kein Virus-Patient hängen lassen, gehe aber das Risiko ein, dass ein gesunder Patient «behandelt» wird.
- Als IT Security möchte ich verhindern, dass zu viel Spam durchkommt, um weiteren Schaden zu verhindern, aber wichtige Dokumente dürfen nicht im Papierkorb landen.
Trotzdem sollte man sich vor Fehl-Klassifikationen nicht verunsichern lassen, sie gehören dazu und erlauben ein erneutes Lernen, um den Algorithmus zu verbessern. Eine erfolgreich angewendete Classification-Applikation kann Zeit und Geld sparen und unnötige Risiken vermindern.