

Beim maschinellen Lernen unterscheiden wir vor allem zwischen zwei Arten von Lernen: Supervised und Unsupervised Learning.
Supervised Learning
Als Grundlage werden Daten genommen, die kategorisiert sind – man spricht hier von «Labels». Ziel ist es, aufgrund von Vergangenheitsdaten oder Beispieldaten das Label von künftigen Daten vorauszusagen. Das Label kann ganz unterschiedliche Werte darstellen, z.B. die Voraussage einer Kategorie (A, B oder C), eine Wahrscheinlichkeit, ein Preis, ein Betrag, eine Ja/Nein-Voraussage, etc. Die Herausforderung beim Supervised Learning ist herauszufinden, welche Eigenschaften der Daten zueinander in Verbindung stehen, so dass das korrekte Label vorausgesagt werden kann. Der daraus entstandene Algorithmus kann dann auf künftige Datensätze angewendet werden, bei denen das Label noch nicht bekannt ist: die Voraussage. Im Supervised Learning gibt es zwei Hauptgruppen von Algorithmen:
- Klassifikation: Voraussage einer Kategorie oder Ja/Nein-Einordnung
- Regression: Voraussage einer Zahl
Evalutaion beim Supervised Learning
Da wir beim Supervised Learning Beispieldaten mit Labels haben, kann das Ergebnis auch bewerten werden. Dabei werden die Beispieldaten zu Beginn der Anwendung in ein Trainings-Set und ein Test-Set aufgeteilt. Das Trainings-Set wird genommen, um das Model zu erstellen und das Test-Set wird verwendet, um das Model zu evaluieren. Bei der Klassifikation kann verglichen werden, ob die richtige Kategorie ermittelt worden ist. Oft wird dabei eine Konfusionsmatrix erstellt:
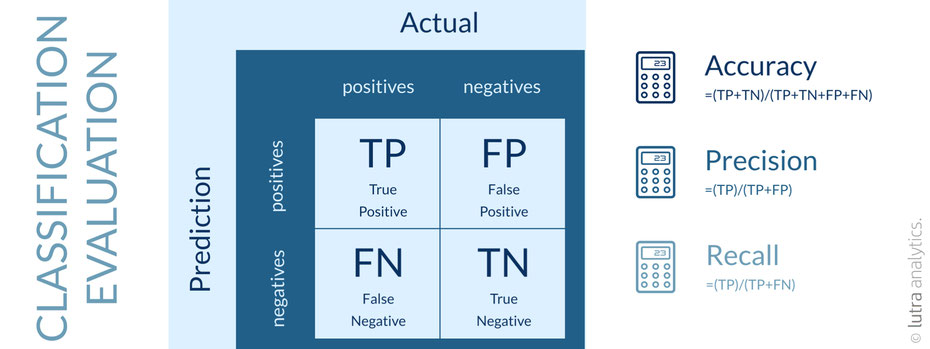
Je nach Voraussage sind unterschiedliche Metriken wichtig, welche die Genauigkeit der Voraussage bewerten: Accuracy, Precision und Recall.
Bei der Regression können die ermittelten Labels ebenfalls evaluiert werden. Da aber das Label eine Zahl ist (also jeglichen numerischen Wert annehmen kann, inkl. Dezimalstellen), kann eine Konfusionmatrix nicht verwendet werden. Stattdessen wird die numerische Entfernung des Labels zum tatsächlichen Label ermittelt. Eine Verteilung dieser Abweichung kann in einem Histogramm dargestellt werden.
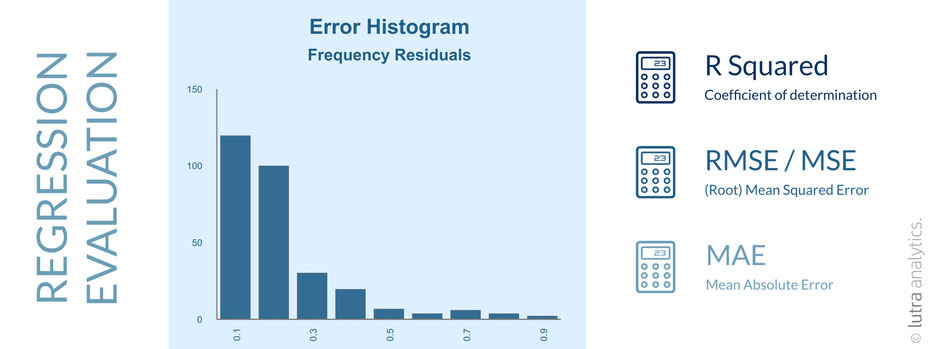
Unsupervised Learning
Ganz anders sieht es beim Unsupervised Learning aus. Hier stehen keine Labels zur Verfügung, die bei einem Training und Test als Überwachung dienen (deshalb «unsupervised»). Stattdessen wird die Datenstruktur auf Gemeinsamkeiten untersucht. Ziel ist es deshalb auch nicht zwingend eine Voraussage zu treffen, sondern mehr über die Daten und ihre Verbindungen zu erfahren. Die bekannteste Methode in dieser Sparte ist Clustering. Hier werden Daten in verschiedene Gruppen («Clusters») eingeordnet, je nach Eigenschaften oder Verfahren kann das Resultat unterschiedlich ausfallen.
Bekannte Anwendungsfälle sind Kundensegmentierung oder Empfehlungssystem anhand von Kaufverhalten oder Profilen. Eine Evaluation wie beim Supervised Learning ist nicht möglich, da nicht bekannt ist, was die richtige Lösung ist.
Fazit
Supervised Learning bietet durch seine «Überwachung» diverse Möglichkeiten zur Kontrolle und Verbesserung des Modells. Beim Unsupervised Learning tappt man etwas im dunkeln und oft merkt man erst in der Produktion, ob eine Segmentierung erfolgreich war oder nicht.
Und was ist mit Ihren Daten? Wofür eignen sie sich? Wir würden uns über einen Austausch freuen.