

Das Konzept der Data Lakes ist nicht neu und dennoch nimmt es immer mehr an Fahrt auf. Nicht zuletzt dank den Cloud-basierten Data Lake Lösungen, welche ein Rundum-Paket liefern. Damit wird die grösste Gefahr bei Data Lakes reduziert, nämlich dass sich der See in einen Sumpf verwandelt. In diesem kurzen Artikel zeigen wir auf, was Data Lakes sind, wie sie neben ein Data Warehouse (DWH) passen – und dieses nicht zwingend ersetzen – und warum insbesondere eine Governance so wichtig ist.
Was sind Data Lakes und warum werden sie benötigt?
Ein Data Lake ist ein Repository, welches jegliche Arten von Daten in ihrem Original-Format speichern kann: strukturierte, semi-strukturierte und unstrukturierte Daten. Strukturierte Daten sind fix definiert und typisiert und werden klassischerweise in Tabellen gespeichert und mit SQL abgefragt. Semi-strukturierte Daten haben teilweise ein spezifisches Format, sind aber nicht erzwungen, z.B. CSV-Files oder die Meta-Daten einer Bild-Datei. Unstrukturiert sind jene Daten, die in kein vordefiniertes Schema passen, z.B. Bilder, Videos, Audio, Fliesstext, etc. und entsprechend schwieriger zum maschinell Verarbeiten sind.
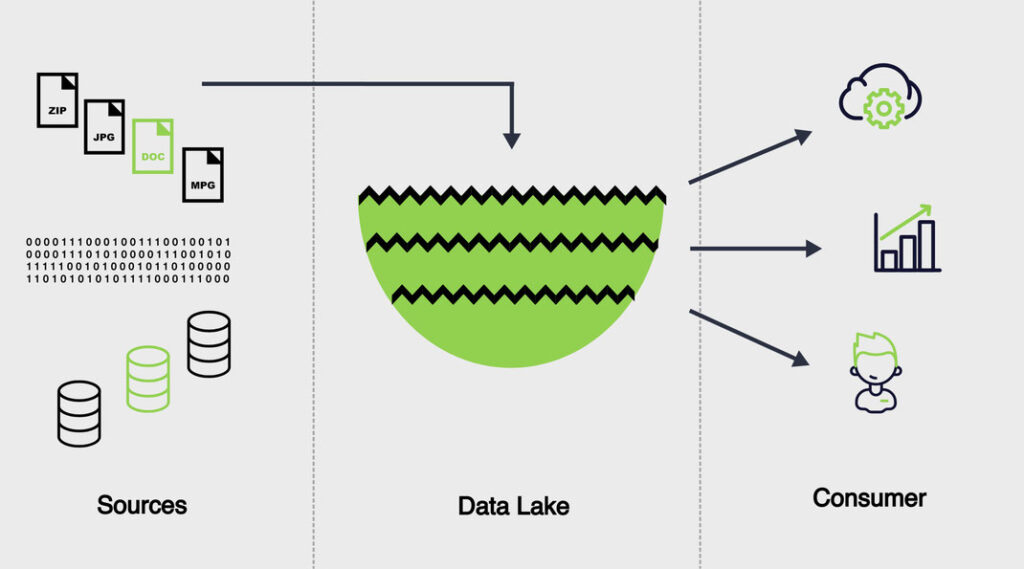
Der Bedarf für ein Data Lake ergibt sich aus verschiedenen Gründen:

Diversität der Daten: In der heutigen digitalen Welt sind nicht alle relevanten Daten strukturiert in einer SQL-Datenbank vorhanden. Streaming-Daten, Social Media Posts, IoT-Daten, Audio oder Video enthalten für ein Unternehmen wertvolle Informationen, welche den Analytics-Teams zur Verfügung gestellt werden sollten.

Zielgruppen und ihre Bedürfnisse: Verschiedene Stakeholder möchten Daten verarbeiten und haben dabei ganz unterschiedliche Bedürfnisse: BI-Spezialisten oder Business Analysten möchten die Daten am liebsten aufbereitet und in vorgegebener Struktur erhalten, um mit ihren Analytics Tools ihre Erkenntnisse zu generieren. Data Scientists sind eher am Roh-Format interessiert und verwenden Sprachen wie Python oder R, um ihre Modelle zu erstellen. Damit nicht für jede Zielgruppe Silos erstellt werden, wird ein Data Lake genutzt, so dass alle die gleichen Daten aus einem Repository beziehen, idealerweise über mehrere Zonen hinweg.

Time-To-Value: Da die Daten beim Einfügen in den Data Lake in ihrem Original-Format beibehalten werden, entfällt die Transformation und somit wichtige Zeit, bis die Daten zum Konsum zur Verfügung stehen. Das heisst nicht, dass zu einem späteren Zeitpunkt nicht doch eine Transformation stattfinden kann/wird (z.B. beim Einsatz eines Data Warehouse aufbauend auf dem Data Lake). Aber nicht alle Konsumenten benötigen eine Transformation. Tasks im Machine Learning-Bereich oder die Verarbeitung von Streaming Daten basieren oft auf dem Rohformat und eine Ressourcen-Aufwändige Transformation via DWH verzögert die Verarbeitung in Echt-Zeit.
Kann ich damit mein Data Warehouse (DWH) ersetzen?
Ersetzt ein Data Lake das Data Warehouse? Nein – aber er könnte! Ein Data Warehouse wird spezifisch für Datenanalyse und BI verwendet. Dabei werden die verschiedenen Quelldaten aufbereitet (Bereinigung, Formatierung, Transformation, Aggregation, etc.) und in der vordefinierten Struktur relational gespeichert. So können die BI-Teams auf den sauberen Daten arbeiten. Wenn nun das DWH mit einem Data Lake kombiniert wird, so werden die Quelldaten erst in den Data Lake geladen, wobei das DWH dann einer von mehreren Konsumenten der Daten im Lake ist. Bei diesem Aufbau werden die beiden Technologien kombiniert.
Es wäre aber auch denkbar, je nach Komplexität des DWH und den darauf bauenden Analytics-Funktionen, dass der Data Lake das klassische DWH ersetzt. In der Data Lake Architektur ist es durchaus Norm, dass ein Staging über mehrere Zonen erfolgt:
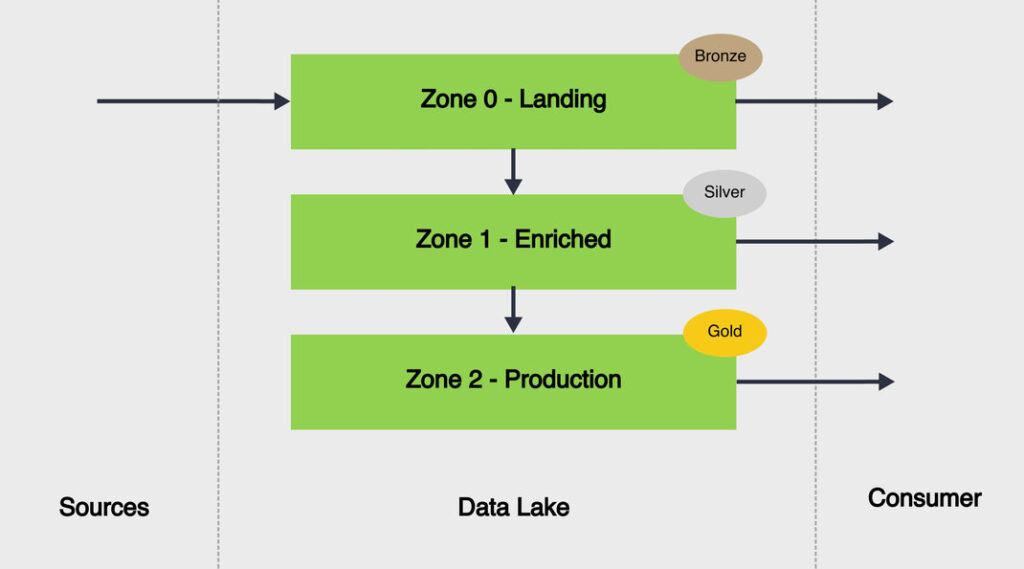
Je nach Konzept oder Cloud-Lösung heissen die Zonen unterschiedlich: Landing, Raw, Curated, Transformed, Deployment, Production, etc. Das Prinzip ist aber immer das gleiche: Es wird über Zonen transformiert, bis die Daten das «Gold-Label» haben, das heisst in Qualität und Wert steigen. Ein DWH kann klassischerweise auf diesen qualitativen Daten aufsetzen resp. einzelne Teile des DWH Staging könnten dadurch obsolet werden. Benötigt jemand dennoch die Daten im rohen, originalen Format, so wird auf eine frühere Zone zugegriffen.
Data Governance is Key
Bei all den Vorteilen ist es aber wichtig, dass der Data Lake nicht zum Datensumpf verkommt. Nämlich dann, wenn unkoordiniert und ohne Überwachung und Weiterentwicklungen Daten in den Lake geladen und genutzt werden. Es ist also zentral, dass Elemente aus der Data Governance thematisiert werden: wer ist für welche Daten verantwortlich, wer hat Zugriff und kann die Daten nutzen, was sind die internen Prozesse und Richtlinien, etc.
Ein paar Beispiele, die daraus resultieren:

Data Catalog: Ein Datenverzeichnis dient dazu, alle Data-Assets in der Organisation zu dokumentieren und zu bewerten. Dies ist ein sehr zentraler Punkt in einem Data Lake, da dieser aufgrund seiner Masse und Diversität klar strukturiert werden soll. Ist einmal klar, welche Daten wo zu finden sind und wer dafür verantwortlich ist, können Zugriffe und Verwendung definiert werden.

Security: Das Zugriffs-Konzept muss wie die Architektur von Beginn weg klar definiert sein: Auf welcher Ebene wird der Zugriff erfolgen (Attribut, File, Container, etc.), wie wird zugegriffen, werden Benutzergruppen und Rollen verwendet, etc. Die Masse an unterschiedlichen Daten an einem Ort (in einem Lake) erzwingt ein sauberes Zugriffs-Konzept, da sonst Daten von unbefugten eingesehen werden können und möglicher Missbrauch entsteht.

Datenqualität: Dass ein Data Lake unstrukturierte Daten zulässt, heisst nicht, dass die Qualität der Daten vernachlässigt werden darf. Eine Transformation und Bereinigung an irgendeiner Stelle muss auch in einem Date Lake stattfinden. Wie bereits vorhergehend erläutert, kann ein Data Lake in verschiedene Zonen aufgeteilt werden und beim Durchlaufen der Zonen durch Transformationen die Qualität steigern.
Fazit
Bei der Nutzung von grossen Datenmengen und unterschiedlichen Formaten, lohnt es sich, mal einen Blick auf das Konzept des Data Lakes zu werfen. Cloud-Provider decken mit ihren Data Lake-Lösungen oft die Anforderungen an die Data Governance ab und bieten Tools und Methodik, um sicher und organisiert seinen Data Lake zu erstellen und zu betreiben.