

Machine Learning (ML) Anwendungen werden gerne über Cloud-Dienste bereitgestellt und bezogen, aber auch lokale (on Premise) Installationen finden nach wie vor Einsatzgebiete. Oft wird dies durch Compliance-Vorgaben oder Datenschutz-Bedenken begründet. Während klassische Anwendungen in Software-Releases aktualisiert werden, gibt es bei ML die Modelle. In der Cloud liefern die Anbieter Tools, um Modelle zu aktualisieren, on Prem aber gilt es eigene Lösungen zu finden.
Modelle müssen aktualisiert werden
Machine Learning bietet sehr interessante Umsetzungen für die Automatisierung von Arbeitsabläufen. Man trainiert ein Algorithmus, damit dieser dann die gegebene Aufgabe selbstständig ausführen kann. Modelle sind die vom Algorithmus abgeleiteten Regeln für die Verarbeitung von Daten.
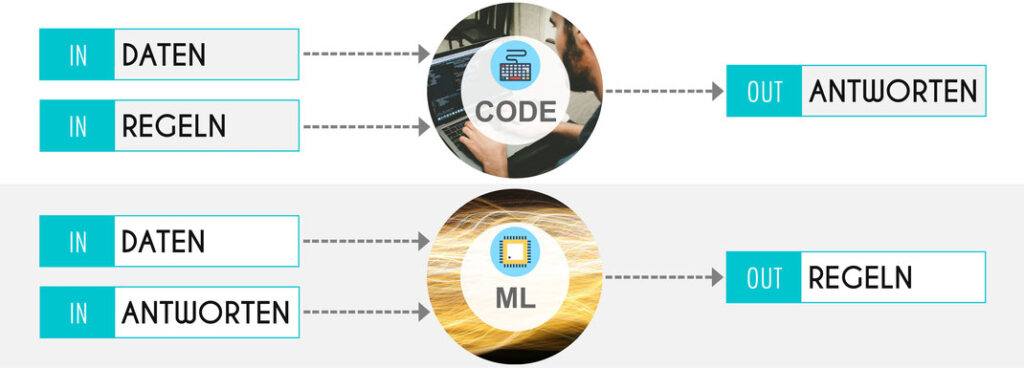
Sobald sich die Daten aber ändern, muss auch das Modell aktualisiert werden. Nehmen wir als Beispiel einen Document Classifier: Beim Training wählt man ein Set von Dokumenten aus und trainiert damit den Algorithmus. Das entstehende Modell ist optimiert auf die ausgewählten Dokumente. Wenn während dem Betrieb nun aber neue Dokumentquellen dazu kommen, oder sich der Kontext leicht ändern sollte, wird der Algorithmus mit dem trainierten Modell immer geringere Trefferquoten erreichen und so Dokumente falsch klassifizieren. Das ist der Grund, warum Modelle aktualisiert werden müssen. Es muss ein neues, der geänderten Ausgangslage angepasstes Modell erstellt werden, damit die Dokumente weiterhin korrekt klassifiziert werden.
Aktualisierungsrhythmus
Anders als bei klassischen Software-Deployments lässt sich bei ML-Modellen schwer ein fixes Zeitintervall für Aktualisierungen definieren: Je nach Einsatzgebiet bleiben die verwendeten Trainings-Daten mehr oder weniger lang gültig. Selbst wenn sich ein gewisses Intervall eingespielt hat, können spezielle Ereignisse schnell Anforderungen an ein neues Modell stellen.
Beispiel: Wenn ein Lebensmittel-Händler mittels ML eine Prediction über Verkaufsumsätze pro Standort erstellt hat, wird er im Frühling 2020 grössere Abweichungen zur Realität festgestellt haben. Der Lockdown hat dazu geführt, dass Kunden ganz andere Einkäufe tätigten. Das Modell muss nun anhand der neuen Einkaufsdaten komplett neu trainiert werden. Daten von den letzten 10 Jahren sind nicht mehr im gleichen Masse belastbar. Daher muss das Modell gerade am Anfang solch einer gravierenden Veränderung öfters neu trainiert werden, bis sich alles wieder etwas eingespielt hat. Laufende Veränderungen in den Bestimmungen können aber das Einkaufsverhalten erneut verändern und so weniger schnell eine “Ruhe in die Daten” bringen.
Es bestimmen viele Faktoren über den Aktualisierungsrhythmus eines Modells und es bedarf nicht immer eines solch einschneidenden Ereignis wie im Beispiel beschrieben. Daher muss eine Aktualisierung eines Modells flexibel erfolgen können, idealerweise ohne einer Bindung an Wartungsfenstern.
Betrieb von ML-Anwendungen
Wer ML-Lösungen für lokale Umgebungen sucht, kann schnell von ein paar Jupiter-Notebooks/-Scripts verführt sein. Es scheint sehr übersichtlich: Modelle lassen sich mittels weniger Python-Scripts erstellen, und via Flask als Service bereitstellen.
Aber Modelle müssen aktualisiert werden! Natürlich kann der Entwickler dem Betrieb einfach eine Checkliste oder Anleitung bereitstellen, mit welcher ein neues Modell eingespielt werden kann. Der Betrieb benötigt aber ein Monitoring oder sonstige Indikatoren, welche den Bedarf für ein zu aktualisierendes Modell aufzeigen. Bei einem einfachen «Checklisten-Ansatz» wird das aber eher reaktiv durch Benutzer-Meldungen erfolgen, als durch ein proaktives Monitoring-System.
Es empfiehlt sich hier aber auf Tools zu setzten, welche spezifisch für diese Problemstellung entwickelt wurden. MLflow, KubeFlow oder Seldon.io (um nur ein paar zu nennen) bieten Anwendungen oder Frameworks, welche nebst einem Monitoring des Modells (Treffer-Genauigkeit) auch die Möglichkeiten bieten, neue Modelle im laufenden Betrieb zu deployen, teilweise sogar mehrere Modelle parallel im Betrieb zu haben.
Ein Tool allein schliesst die Diskussion aber nicht: Es gilt Knowhow für ML-Lösungen aufzubauen, nicht nur in der Entwicklung, sondern gerade auch im Betrieb. Wenn die Funktionsweise und Anforderungen an ML-Lösungen nicht verstanden werden, ist ein Betrieb nicht gewährleistet. Das gilt für lokale Implementierungen genauso wie auch für Cloud-basierte Ansätze.