

Viele Unternehmen sehen sich täglich einer Menge an eingehenden Dokumenten ausgeliefert. Mit digitalen Prozessen und Archiven wächst diese Menge und eine manuelle Zuordnung nach Art des Dokuments – oder eben «Klassifizierung» – kann viel Zeit beanspruchen. Eine solche Triage kann jedoch automatisiert werden, sodass nachfolgende Aktionen ebenfalls automatisch eingeleitet werden können (z.B. Weiterleitung an die entsprechende Verteilergruppe). Somit können wir automatisch Dokumente klassifizieren.
«Document Classification» ist eine klassische Aufgabe des Machine Learnings. Basierend auf bereits klassifizierten Dokumenten wird ein Modell erstellt und trainiert, welches verwendet wird, um künftige Dokumente automatisch einzuordnen.
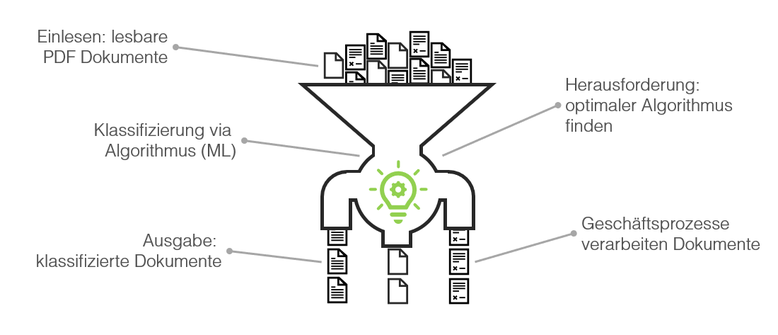
Die Graphik zeigt wie eine Vielfalt an unterschiedlichen Dokumenten eintreffen und durch die Machine Learning Logik entsprechend sortiert wird.
Ein klassisches Szenario
Wir haben ein Proof-of-Concept in unserer Firma gemacht und dabei konnten wir verifizieren, dass bereits bei einer kleinen Menge an klassifizierten Dokumenten ein Training möglich ist, sodass zufriedenstellende Ergebnisse erreicht werden können. Wir haben folgende Kategorien für unsere Dokumente bestimmt:
- Rechnung
- Versicherungspolice
- Lohnabrechnung
Das Ziel ist es, eine neue Rechnung, Police oder Lohnabrechnung zu klassifizieren, sodass das Dokument automatisch an die entsprechende Verarbeitungsstelle weitergeleitet werden kann. Wir haben dazu ein Datenset mit weniger als 100 Dokumenten verwendet und konnten Trefferquoten von bis zu 90% erreichen.
Was passiert im Hintergrund?
Bei dieser Aufgabe des «Natural Language Processings» werden die Texte in den Dokumenten auseinander genommen und statistisch verglichen: Welche Wörter erscheinen in welchem Kontext und welche Relevanz haben sie verglichen mit den anderen Dokument-Kategorien. Je nach Algorithmus im Modell wird dann bestimmt, wie ein Text künftig eingeordnet werden kann. Bei dieser Art von Klassifizierung spielt lediglich der Text, nicht aber die Anordnung oder das Layout des Dokuments eine Rolle.
Entscheidende Faktoren für den Erfolg
Das Resultat hängt stark von verschiedenen Faktoren ab, welche bei jedem Unternehmen anders gegeben oder gefordert sind.
- Vielfalt an unterschiedlichen Kategorien
- Unterscheidbarkeit des Inhalts
- Verfügbare Datenmenge
- Qualität der Daten/Texte
- Angewendeter Algorithmus
Natürlich wächst die Komplexität, wenn es massiv mehr Kategorien zu erkennen gibt. Entscheidend ist aber oft nicht die Anzahl der Kategorien, sondern wie klar sie differenzierbar sind. Wenn die Unterschiede im Text der Dokumente marginal sind, dann braucht es mehr Dokumente zum Trainieren und feinere Algorithmen, um die Dokumente klar einzuordnen. Somit sind die Faktoren und Aussage über Aufwand und Komplexität voneinander abhängig.
Sie haben die Dokumente – wir bauen die Logik
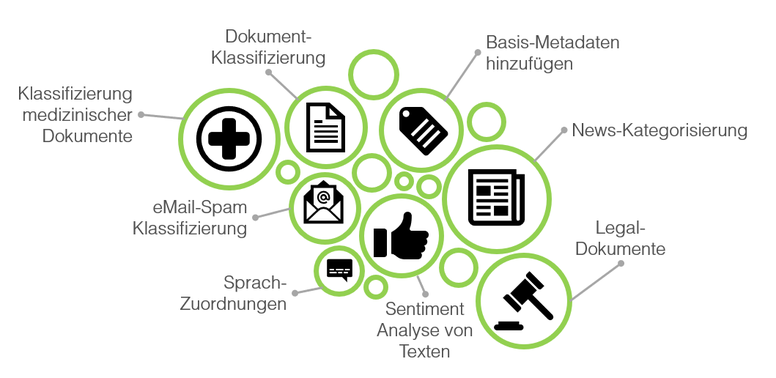
Anwendungsmöglichkeiten in diesem Bereich gibt es viele. Haben Sie eine signifikante Menge an Dokumenten, welche Sie automatisch klassifizieren möchten und somit manuelle Triage erleichtern? Bereits mit wenig Aufwand können wir abklären, wie schnell sich Ihre Dokumente automatisch klassifizieren lassen und was benötigt wird, um diese voll umfänglich in Ihre Applikationen und Arbeitsalltag zu integrieren.