

Bei vielen aussergewöhnlichen Machine Learning Applikationen ist Deep Learning im Spiel. Die Genauigkeit der Voraussagen ist in der Tat erstaunlich. Dennoch haben Deep Learning Applikationen einen entscheidenden Nachteil gegenüber traditionellen Machine Learning Applikationen: Es ist schwierig bis nicht nachvollziehbar, wie ein bestimmtes Resultat zustande kommt. Man spricht hier von einer Black Box, da wir nicht wissen, was darin genau vor sich geht.
Wie unterscheidet sich Deep Learning von traditionellem Machine Learning?
Im Machine Learning gibt es viele verschiedene Algorithmen, um unterschiedlichste Problemstellungen anzugehen. Einige Beispiele dazu sind Lineare Regression, Decision Trees, Clustering, Neuronale Netze, etc.
Deep Learning ist eine Unterdisziplin des Machine Learnings und basiert auf dem Konzept von Neuronalen Netzen. Wenn ein neuronales Netz eine bestimmte Tiefe und Komplexität aufweist, spricht man von Deep Learning.
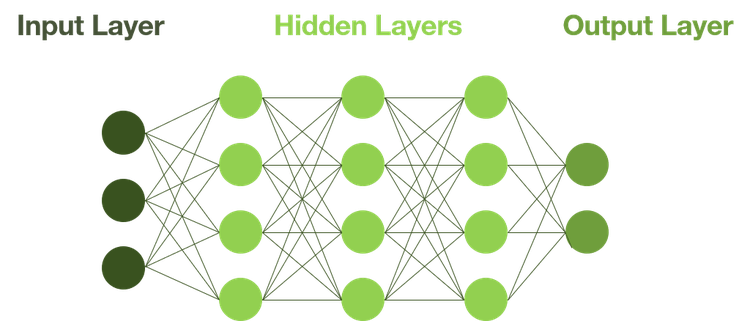
Ursprünglich orientiert sich das neuronale Netz am menschlichen Gehirn. Es empfängt Input-Daten von aussen, verarbeitet diese über mehrere Schichten und gibt am Schluss das Resultat über den Output Layer aus. Beim Deep Learning gibt es sehr viele Hidden Layers mit vielen Knoten und somit erlaubt es ein «tiefes Lernen». Durch weitere Funktionen wie die «Back Propagation» werden die Funktionen innerhalb der Layers zudem automatisch optimiert, was die Gesamtlösung noch genauer macht.
Von schwarzen und weissen Schachteln
Genau diese Tiefe und Komplexität führt nun zu dieser Black Box, denn wir überlassen es grösstenteils dem Algorithmus, wie die Knoten innerhalb miteinander funktionieren.

Bei traditionellen Modellen, wie z.B. bei Decision Trees, können wir das Konstrukt relativ einfach nachvollziehen und interpretieren. Hier wissen wir nicht nur um die unterliegende Statistik und Mathematik, sondern haben auch ein intensives Feature Engineering durchgeführt. Wir wissen also, welche Daten in das Modell einfliessen und wie sie im Modell verwendet werden. Ist diese Transparenz gegeben, so spricht man von «White Box» Machine Learning.
Fehlt die Interpretierbarkeit, so fehlt die Akzeptanz
Das primäre Ziel einer Machine Learning Applikation ist es, gute Ergebnisse zu liefern. Deep Learning Applikationen liefern oft herausragende Ergebnisse. Es ist nun aber so, dass dies häufig nicht mehr ausreicht. Mit der Einführung von Machine Learning Applikationen in die Business Welt, verlässt man sich mehr und mehr auf Maschinen und Automationen. Umso wichtiger ist es, dass man versteht, was vor sich geht, um einerseits die Kontrolle zu behalten, andererseits aber auch um ethischen Aspekten gerecht zu werden. Die Menschen möchten wissen, was mit ihren Daten geschieht. Firmen können es sich nicht leisten, Gruppen aufgrund von persönlichen Eigenschaften zu benachteiligen, die in einem solchen Modell möglicherweise verwendet werden. Eine Bank zum Beispiel muss erklären können, warum eine Person als kreditfähig eingeordnet wird und eine andere nicht. Fehlt die Interpretierbarkeit, so fehlt es an Akzeptanz und dies wiederum ist eine der wichtigsten Faktoren für ein erfolgreiches Machine Learning Projekt.
Somit gilt es abzuwägen, wie weit sensitive Daten verwendet werden und welche sozialen Auswirkungen eine solche Applikation oder Funktion mit sich zieht. Je nach dem sollten Einbussen in der Performance zugunsten der Transparenz in Kauf genommen werden.