

Eine der Hauptaufgabe von Data Analytics ist es, neues oder verstecktes Wissen zu finden. Eine gängige Definition zum Vorgehen dieser «Knowlede Extraction» ist der Prozess «Knowledge Discovery in Databases», kurz KDD. Die Definition dazu ist bereits über 20 Jahre alt und dennoch sind die darin enthaltenen Schritte immer noch die gleichen, wie wir sie heute in Machine Learning Projekten durchlaufen. Wir stellen den Knowledge Discovery Process vor.
Der Prozess startet, wie so vieles, mit einer Zieldefinition dessen, was wir zu erreichen wünschen oder erhoffen. Oftmals weiss man erst, was man sucht, wenn man es gefunden hat. Dennoch sollte eine Abgrenzung gemacht werden, ansonsten ist es eine Suche nach der Nadel im Hauhaufen.
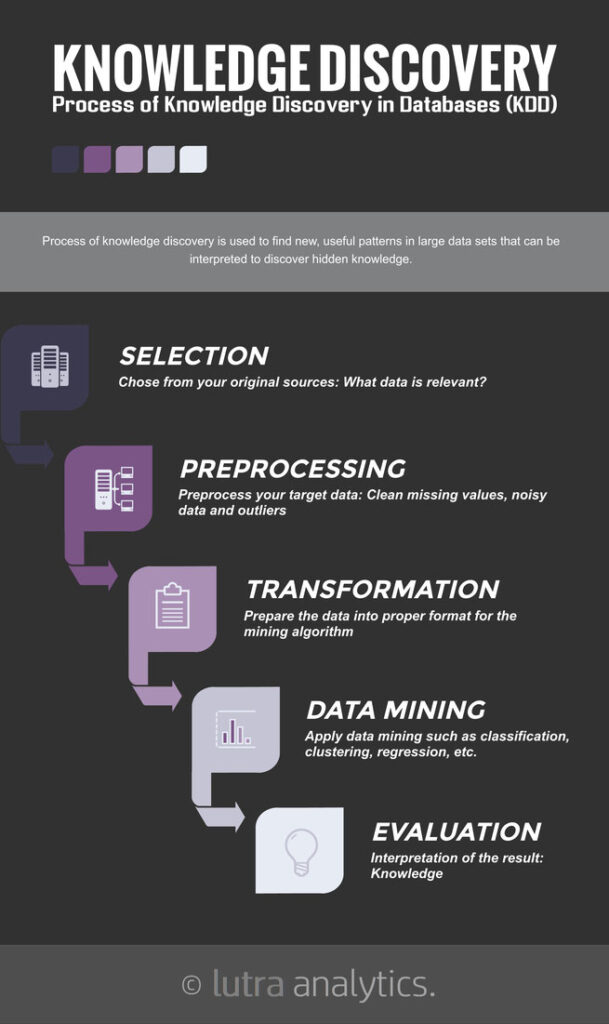
Schritt 1: Selection
Firmen verfügen heute über riesige Datenmassen, sowohl strukturiert als auch unstrukturiert. Im ersten Schritt müssen jene Datenquellen identifiziert werden, welche für die angestrebte Wissensgewinnung relevant sind.
Schritt 2: Preprocessing
Eine der aufwändigsten Aufgaben überhaupt ist das Bereinigen der ausgewählten Daten. Dazu gehört unter anderem das Korrigieren von fehlerhaften oder ganz fehlenden Daten, als auch das Entgegensteuern von Ausreisser, welche die Statistik verfälschen könnten. Auch hier gilt: Die Qualität der Daten ist wichtig, denn auch der beste Machine Learning Algorithmus findet nichts sinnvolles, wenn die unterliegenden Daten fehlerhaft oder unvollständig sind.
Schritt 3: Transformation
Sind die Daten bereinigt, müssen sie so transformiert werden, dass sie für den Algorithmus interpretierbar und verwendbar sind. Das beinhaltet die Normalisierung und Standardisierung (von einigen Algorithmen zwingend nötig), aber auch das Hinzufügen oder Reduzieren von Attributen und Dimensionen.
Schritt 4: Data Mining
Das Kernstück des Prozesses ist das Data Mining, also die Auswahl und Anwendung eines Algorithmus. Das bedeutet: Classification, Regression, Clustering, Anomaly Detection, etc. Je nach Methode gibt es dann unterschiedliche Algorithmen, die je nach Daten und Problemstellung sinnvoll oder weniger sinnvoll angewendet werden können.
Schritt 5: Evaluation
Der letzte Schritt beinhaltet die Evaluation und Interpretation der Resultate, also die Muster, welche entdeckt worden sind. Entdeckungen in diesem Schritt können dazu führen, dass vorhergehende Schritte nochmals in abgeänderter Form durchlaufen werden.
Der Prozess ist iterativ und kann als roter Faden benutzt werden. Nicht selten findet man Antworten zu Fragen, die man gar nicht gestellt hat – und dennoch sinnvoll genutzt werden können. Möchten Sie mehr Wissen aus ihren Daten ziehen? Gerne unterstützen wir sie im Gesamtprozess oder in Teilschritten. Wir freuen uns auf Ihre Anfrage.
Referenz KDD Definition: Maimon, O and Rokach, L (2010) Data Mining and Knowledge Discovery Handbook, 2nd ed. Springer.